
Introduction
Most AI benchmarks measure response speed, penalize cost, and treat a tidy markdown summary as a successful result. But for high-stakes analytical work where a wrong answer carries real financial consequences, what actually matters is depth of reasoning, data fidelity, and output you can act on. In wind turbine siting specifically, the unit that matters is precision: a recommendation that lands within a few kilometres of a genuinely viable site is actionable, while one that is only broadly “in the right region” is not.
We built Globeholder AI’s Thinking Lab™ around those principles, and then we put it head-to-head with Anthropic’s Claude and OpenAI’s ChatGPT to see how the tradeoffs play out in practice.
Thinking Lab™ differs from the text-based models in a fundamental way. Rather than reasoning about wind and terrain from learned text, it performs Type-2 physical reasoning directly over geospatial data layers: Digital Elevation Model (DEM) terrain and slope rasters, satellite imagery and land-cover classification, and physically simulated wind-resource fields. The two text-based LLMs reason about the region from training-derived knowledge; Thinking Lab™ reasons over what the land and atmosphere actually look like. This benchmark was designed to test whether that distinction shows up in measurable siting accuracy.
We started with the question of where to site new utility-scale wind turbine installations within a central New Mexico region of interest — an area with strong, well-characterized wind resource and an established fleet of operating turbines that serves as ground truth.
At a Glance: The Models
| Company | Product + Model | Notes |
|---|---|---|
| Globeholder.ai | Thinking Lab™ | Type-2 physical reasoning platform |
| Anthropic | Claude Opus 4.6 | Latest Claude family model |
| OpenAI | ChatGPT-5.4 | Latest GPT family model, deep research mode |
The Approach: Task Definition
To evaluate geospatial reasoning performance, we designed a task focused on optimal wind turbine site identification within a constrained, real-world region. Models were asked to:
Identify and rank optimal locations for new wind turbine installations by jointly analyzing wind resource, terrain and slope, ruggedness, land-use constraints, and accessibility. For each recommendation, explain the key drivers behind site selection.
Each model returned its top candidate locations as latitude/longitude coordinates, enabling direct spatial comparison against the reference fleet.
Evaluation Methodology
To assess prediction quality, we used a distance-based accuracy benchmark grounded in real-world infrastructure:
- Reference turbine locations were drawn from the U.S. Wind Turbine Database (USWTDB V8.3), filtered to the region of interest (1,289 operating turbines).
- For each predicted point, we computed the Haversine great-circle distance to the nearest reference turbine.
- The primary accuracy measure is threshold-based hit-rate: the share of predictions falling within fixed radii of an operating turbine (5 km, 10 km, 20 km, 50 km). Short radii are the decision-relevant ones — a 5 km hit corresponds to a site a developer could actually pursue.
- We additionally report standard distributional error metrics — Median, Mean Absolute Error (MAE), Root Mean Square Error (RMSE), and Standard Deviation — for completeness.
Thinking Lab™ generated its predictions by reasoning directly over physical data layers for the region: DEM-derived terrain elevation, slope and ruggedness; satellite-derived land-cover and land-use constraints; and physically simulated wind-resource fields. The two text-based models received the same task definition and bounding box and returned ranked coordinate lists from their internal reasoning. All three models were evaluated over an identical set of 120 candidate points each, against the same reference fleet, so the comparison is like-for-like.
Results: Precision Site Identification
The headline result is short-radius accuracy — how often a model’s recommendation lands close enough to be acted on. This is where Thinking Lab’s Type-2 physical reasoning separates most clearly from the text-based models.
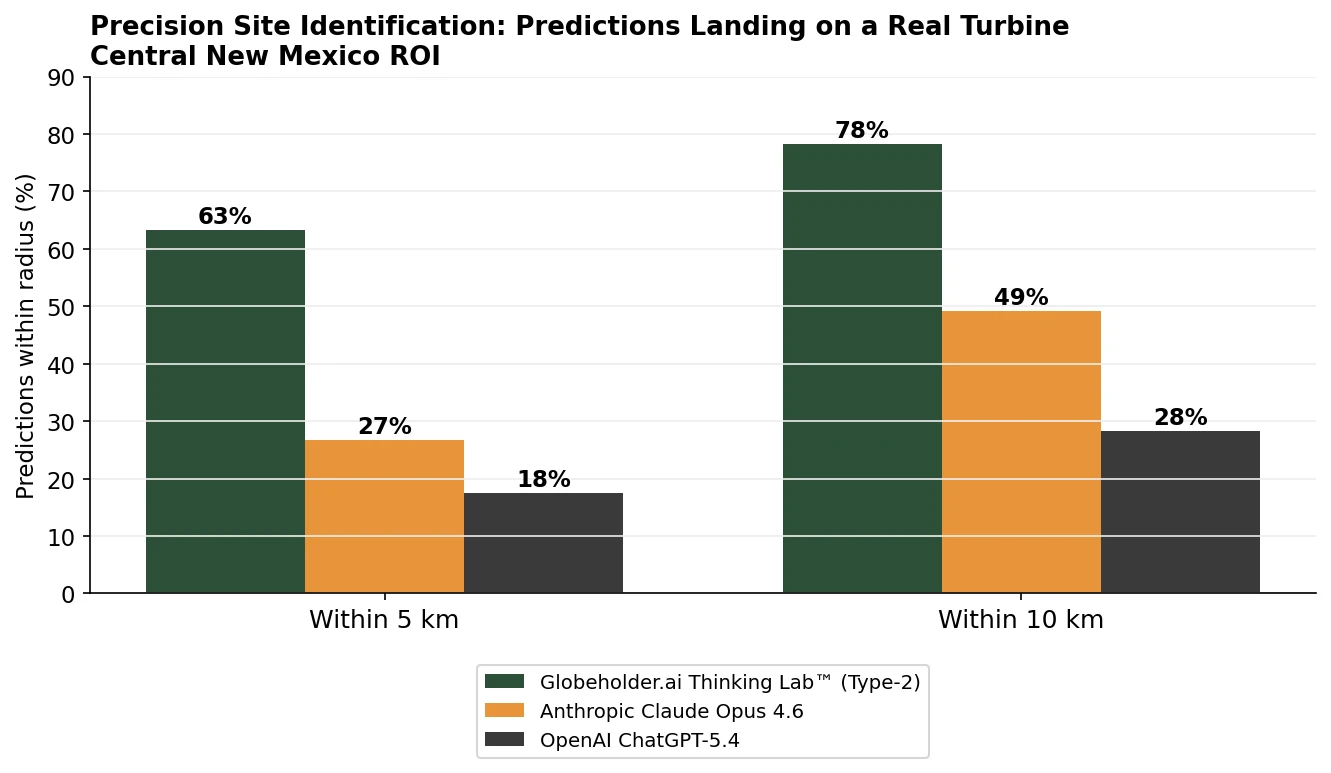
Within 5 km, Globeholder AI Thinking Lab™ placed 63% of its predictions directly on a real, operating turbine — more than double Anthropic Claude Opus 4.6 at 27% and roughly three times OpenAI ChatGPT-5.4 at 18%. Within 10 km the ordering holds: Thinking Lab™ reaches 78%, against 49% for Claude and 28% for ChatGPT. In the radius band that actually governs a siting decision, Thinking Lab™ is the only model placing the clear majority of its recommendations on viable ground.
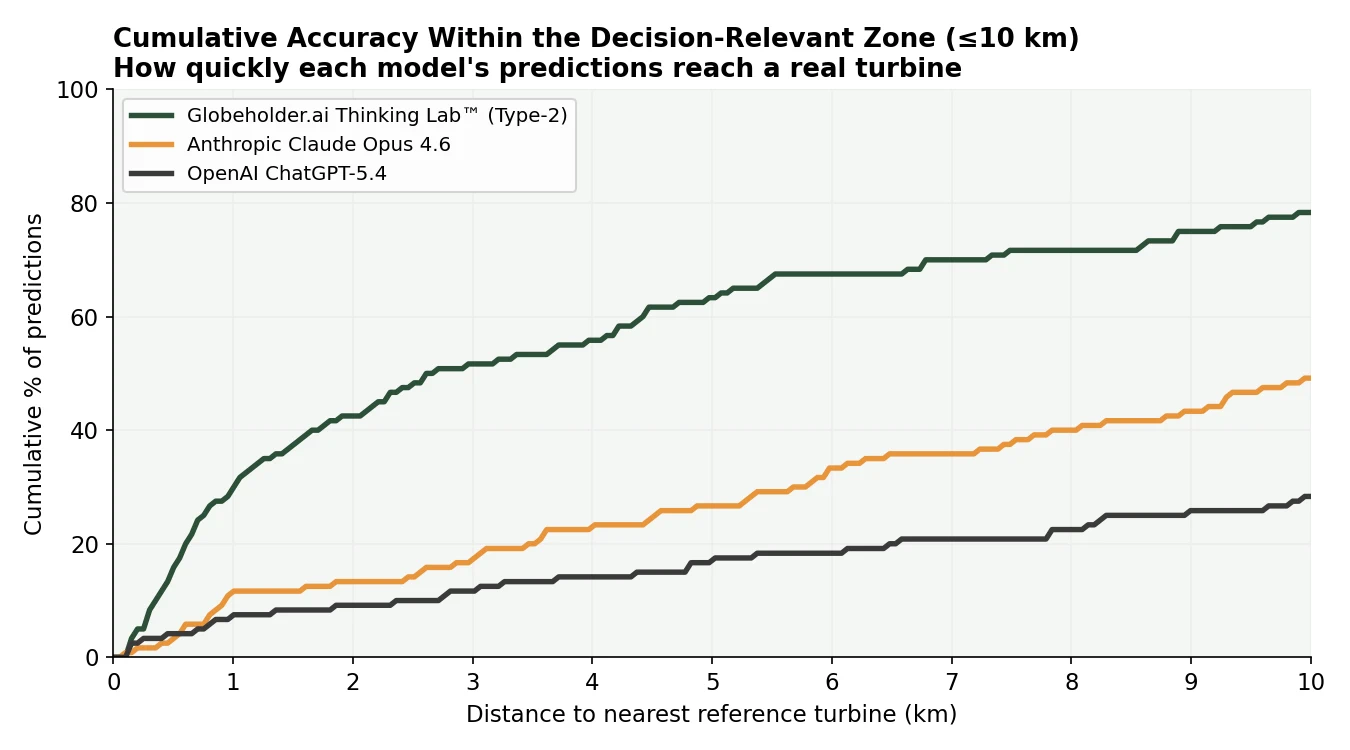
The cumulative accuracy curve makes the same point continuously. Across the entire decision-relevant zone up to 10 km, Thinking Lab’s curve sits well above both text-based models — it accumulates correct predictions fastest at every short radius, the range in which a recommendation remains practically useful for siting.
Spatial View: Where the Predictions Land
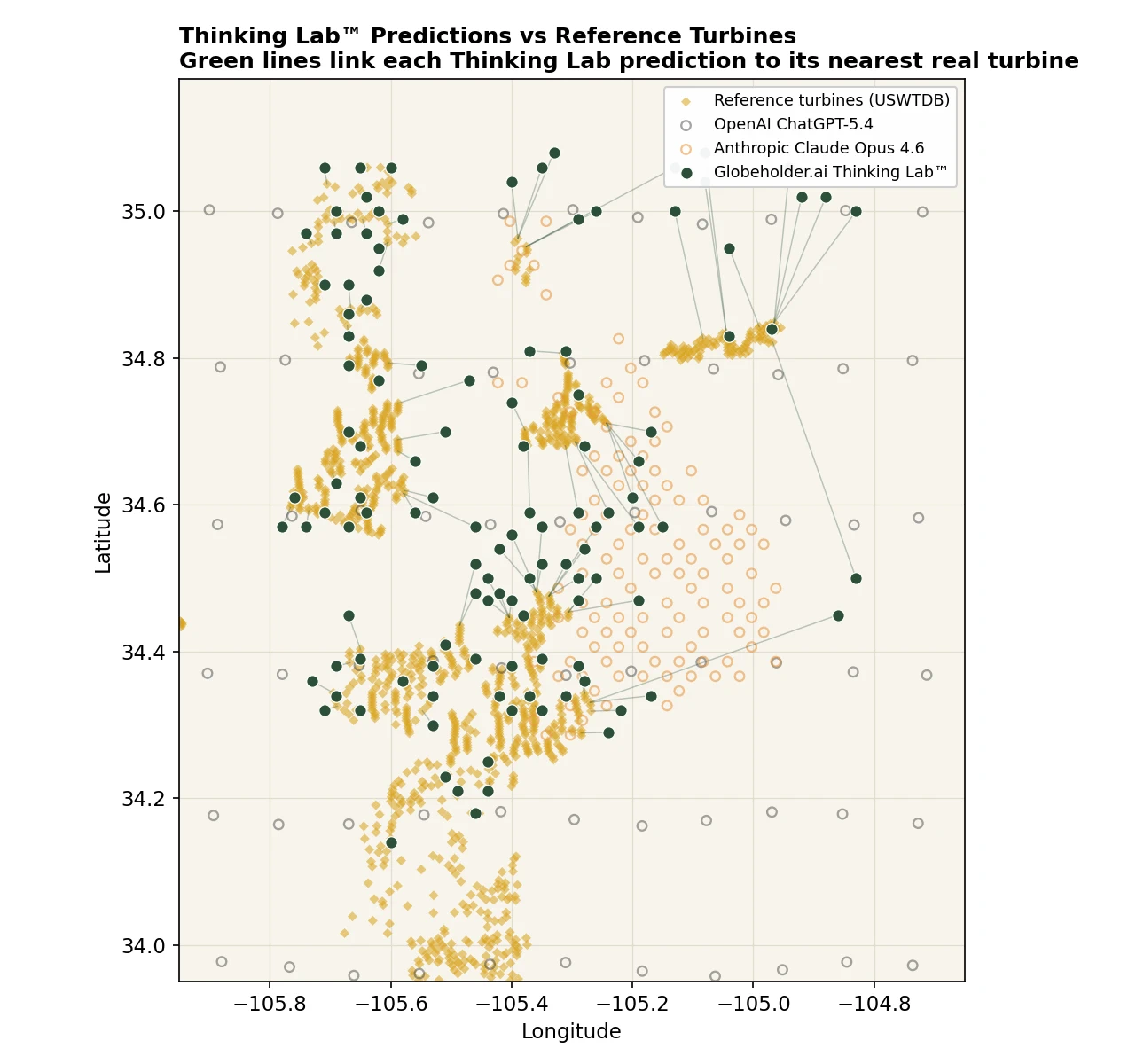
The map below plots the predictions over the operating turbine fleet. Each Thinking Lab™ point is joined to its nearest real turbine by a short connector line — the shorter the line, the closer the prediction. Thinking Lab’s recommendations sit directly on the turbine clusters, with consistently short connectors. The text-based models, shown faded for contrast, drift away from the fleet: Claude’s points concentrate in open ground between clusters, and ChatGPT’s fall on an evenly spaced grid that largely ignores where turbines actually are.
Full Distance Benchmark
For completeness, the full set of distance metrics across all 120 candidate points per model is reported below.
| Metric | Thinking Lab™ | Claude Opus 4.6 | ChatGPT-5.4 |
|---|---|---|---|
| MAE (Mean) | 6.50 km | 11.84 km | 27.89 km |
| Median | 2.64 km | 10.19 km | 23.27 km |
| RMSE | 11.09 km | 14.64 km | 35.56 km |
| Std Dev | 8.99 km | 8.62 km | 22.05 km |
| Within 5 km | 76 / 120 | 32 / 120 | 21 / 120 |
| Within 10 km | 94 / 120 | 59 / 120 | 34 / 120 |
| Within 20 km | 110 / 120 | 95 / 120 | 55 / 120 |
| Within 50 km | 120 / 120 | 120 / 120 | 96 / 120 |
Thinking Lab™ leads on every accuracy metric in the table: lowest MAE (6.50 km), lowest median (2.64 km), lowest RMSE (11.09 km), and the highest hit-rate at every threshold, including a clean 120 of 120 within 50 km. Its standard deviation is essentially level with Claude’s despite reaching far closer on average, indicating both more precise central placement and fewer large misses.
Composite Proximity Score
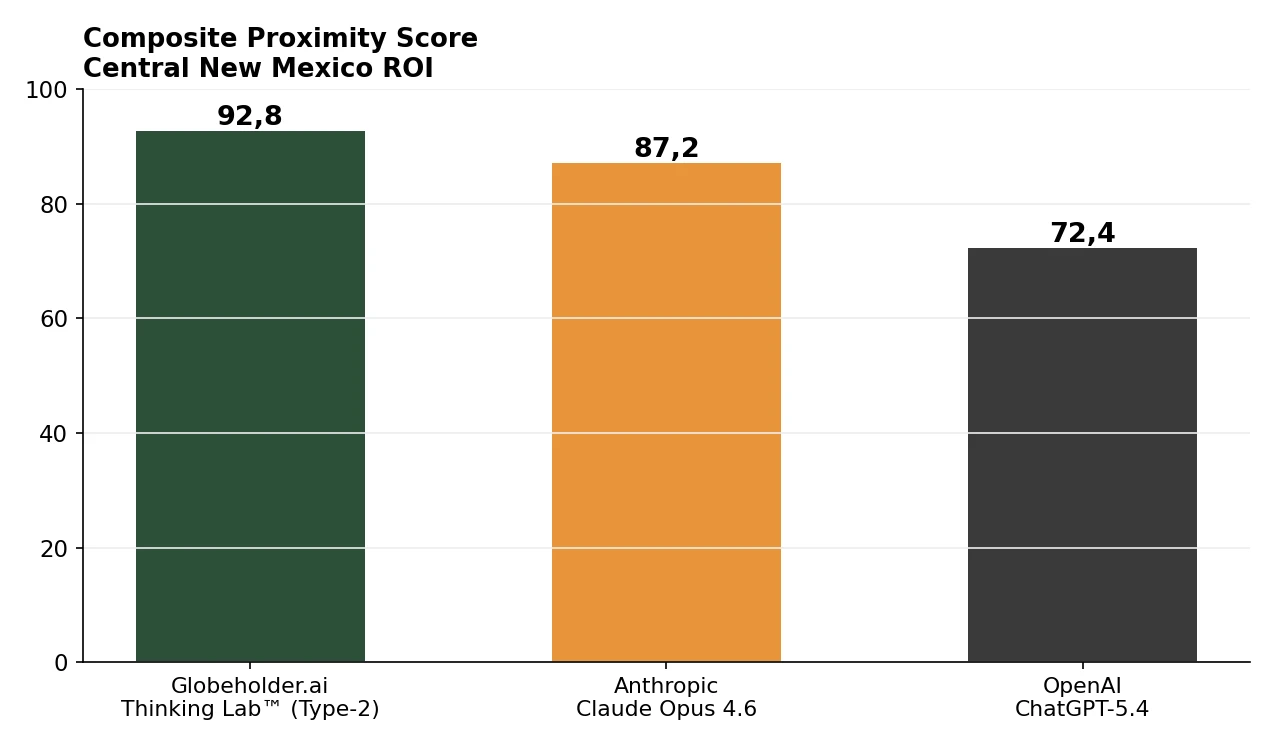
On the composite proximity score, Globeholder AI Thinking Lab™ reached 92.8 out of 100, ahead of Anthropic Claude Opus 4.6 at 87.2 and OpenAI ChatGPT-5.4 at 72.4.
Top 10 Predicted Site Coordinates
| # | Thinking Lab™ | Claude Opus 4.6 | ChatGPT-5.4 |
|---|---|---|---|
| 1 | 34.50, -105.37 | 34.49, -105.20 | 33.36, -104.61 |
| 2 | 34.47, -105.44 | 34.53, -105.18 | 33.57, -104.60 |
| 3 | 34.52, -105.35 | 34.51, -105.22 | 33.77, -104.61 |
| 4 | 34.52, -105.31 | 34.55, -105.22 | 33.96, -104.62 |
| 5 | 34.97, -105.69 | 34.43, -105.24 | 34.16, -104.60 |
| 6 | 34.88, -105.64 | 34.51, -105.16 | 33.34, -104.73 |
| 7 | 34.45, -105.38 | 34.63, -105.22 | 33.56, -104.72 |
| 8 | 34.75, -105.29 | 34.57, -105.20 | 33.77, -104.72 |
| 9 | 34.92, -105.62 | 34.47, -105.14 | 33.97, -104.74 |
| 10 | 34.74, -105.40 | 34.45, -105.18 | 34.38, -104.60 |
Interpretation
This benchmark highlights a key distinction in model capabilities:
- Text-based reasoning models (Claude, ChatGPT) reason about a region from training-derived knowledge. They produce plausible, broadly correct placement, but their accuracy degrades at the short radii that govern an actual siting decision — most clearly in ChatGPT’s wide spread and weak 5 km hit-rate.
- Type-2 physical reasoning systems like Globeholder AI’s Thinking Lab™ reason over the data directly — DEM terrain and slope, satellite land-cover, and simulated wind-resource fields. Integrating these layered physical signals produces precise, decision-grade site selection, which is exactly what the short-radius results demonstrate.
Conclusion
The results reflect a fundamentally different approach to answering where to place wind turbines. The text-based models returned ranked coordinate lists derived from reasoning about wind and terrain, while Globeholder AI’s Thinking Lab™ reasoned directly over physical data — DEM terrain and slope, satellite land-cover, and simulated wind-resource fields — rather than about it.
The benchmark confirms the difference quantitatively, and it shows up exactly where it matters. In the 5 km band that governs an actionable siting decision, Thinking Lab™ placed 63% of its predictions on an operating turbine — well ahead of Claude (27%) and ChatGPT (18%) — and led on median distance (2.64 km) and composite proximity score (92.8 of 100). The strength of the short-radius and median results, rather than a single lucky minimum, demonstrates consistent precision across the full candidate set — the kind of accuracy that turns a model output into a site a developer can actually pursue.
Sign up for Globeholder AI’s Platform Access to our platform.